文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。它是一种与平台和语言无关的应用程序接口(API),它可以动态地访问程序和脚本,更新其内容、结构和www文档的风格(HTML和XML文档是通过说明部分定义的)。文档可以进一步被处理,处理的结果可以加入到当前的页面。DOM是一种基于树的API文档,它要求在处理过程中整个文档都表示在存储器中。另外一种简单的API是基于事件的SAX,它可以用于处理很大的XML文档,由于大,所以不适合全部放在存储器中处理。
精选百科
本文由作者推荐
文档对象模型
处理可扩展置标语言的标准编程接口
中文名
文档对象模型
外文名
Document Object Model
简称
DOM
定义
可扩展置标语言
定义
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。它是一种与平台和语言无关的应用程序接口(API),它可以动态地访问程序和脚本,更新其内容、结构和www文档的风格(HTMl和XML文档是通过说明部分定义的)。文档可以进一步被处理,处理的结果可以加入到当前的页面。DOM是一种基于树的API文档,它要求在处理过程中整个文档都表示在存储器中。另外一种简单的API是基于事件的SAX,它可以用于处理很大的XML文档,由于大,所以不适合全部放在存储器中处理。
模型及扩展
文档对象模型DOM
DOM即文档对象模型,是W3C制定的标准接口规范,是一种处理HTML和XML文件的标准API。DOM提供了对整个文档的访问模型,将文档作为一个树形结构,树的每个结点表示了一个HTML标签或标签内的文本项。DOM树结构精确地描述了HTML文档中标签间的相互关联性。将HTML或XML文档转化为DOM树的过程称为解析(parse)。HTML文档被解析后,转化为DOM树,因此对HTML文档的处理可以通过对DOM树的操作实现。DOM模型不仅描述了文档的结构,还定义了结点对象的行为,利用对象的方法和属性,可以方便地访问、修改、添加和删除DOM树的结点和内容 。
DOM树扩展
根据W3C的定义,DOM树结点的属性包括标记名(nodeName)、结点类型(node Type,取值为TagTxt)、结点内容(data)、父结点对象集合(parent Node)、子结点对象集合(firstChild,lastChild)、兄弟结点对象集合(previous Sibling,nextSibling)等。DOM树结点的这些属性给出了页面的基本内容和结构信息,但不能反映标签、属性以及内容等与主题的相关程度,因而缺乏主题提取所需的语义。对DOM树扩展的总体思路为:考虑HTML页面标签的类别,以及标签属性值对页面主题信息的影响,将这种影响纳入对页面内容要素的计算中,对DOM树结点进行语义扩展,同时引入结点影响度因子来刻画该结点在树中的重要程度。
DOM树结点语义扩展
为了增加DOM树结点与页面主题信息相关程度的语义信息,计算结点内容的重要度,将HTML标签的类别(Category)、非链接文字数(WordNum)、超链接数(LinkNum)、属性集(Attibution)和影响度因子(Influence)等属性添加到结点中,扩展其语义。HTML标签依据其作用可分为5类:
描述标题及页面概要信息的标签:如〈title〉、〈meta〉等。
规划网页布局的标签:如〈table〉、〈tr〉、〈td〉、〈p〉、〈div〉等,其作用是描述网页内容的布局结构。
描述显示特点的标签:如〈b〉、〈I〉、〈strong〉、〈h1〉-〈h6〉等,其作用是强调重点内容,引起人们注意。
超链接相关的标签,表示网页间的内容相关性信息。
其他标签,如设置图像的标签〈img〉,在文本提取时将忽略这类标签。
根据HTML标签在刻画网页特征时的语义功能,将DOM树结点分为6种类别:标题类(TITLE)、正文类(CONTENT)、视觉类(VISION)、分块类(BLOCK)、超链类(LINK)和其他类(OTHER),不同类的结点对Web信息提取的重要度不同。
标题类(TITLE):指HTML文档中标题标签的专有类别。
正文类(CONTENT):指包含网页正文内容的标签类别,如包含文字的〈td〉标签。
视觉类(VISION):指描述页面显示特性的标签类别,如〈b〉、〈strong〉等。
分块类(BLOCK):指用于网页内容分块的标签类别,如〈table〉、〈tr〉等。
超链类(LINK):指包含超链接的标签类别,如〈a〉。
其他类(OTHER):指不属于以上5种类别的标签类型。

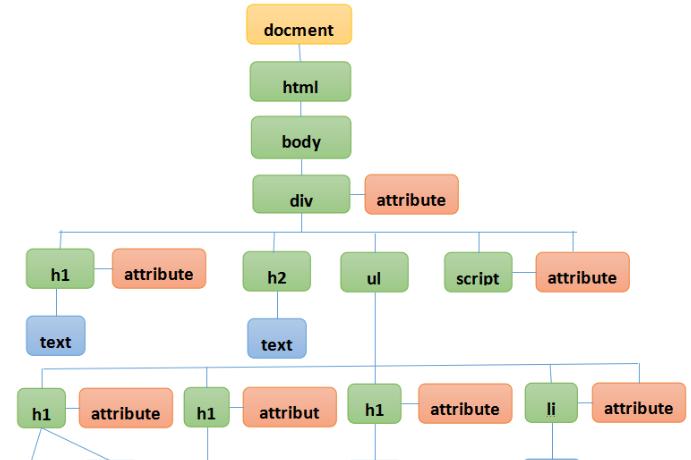
图1 扩展后的DOM树结点结构
以上6类结点对页面主题的重要度依次降低。扩展后的DOM树结点结构如图1所示。
结点影响度因子
Web页面的有效内容大多存在DOM树的叶结点中,DOM树中的其余结点主要用于表示内容分块及页面的外观特性。在已有的页面信息提取方法中,对这些结点往往只考虑内容分块作用,而忽略了视觉结点对页面内容的影响。实际上,网页设计者通常会利用显示标签以及标签属性强调重点内容,不妨称其为强调标签和标签强调属性,例如〈b〉标签,或〈font〉标签的size属性。此外,不同类别结点对其子孙结点内容块的影响也是不同的。例如,以标题类结点为祖先结点的内容块,其重要程度应更高。为了评判DOM树中结点对内容的影响程度,定义了结点影响度因子。
定义1(DOM树结点影响度因子)表示结点对内容影响的相对程度,用Influence(node)表示,Influence(node) ∈。该值越大,表明影响程度越高。
结点影响度因子的确定要综合考虑结点类别和标签强调属性,其初值按TITLE,CONTENT,VISION,BLOCK,LINK,OTHER类别降序排列。可构造影响度因子初值向量Initvlale。同时结点影响度因子具有传递性,即某结点的影响度因子值应向其子结点传递。因此,叶结点的影响度因子可由下式计算:Influence(leaf) =∑ki=Influence(Ancestori)其中,Ancestori是叶结点的祖先结点,k为祖先结点数。
接口
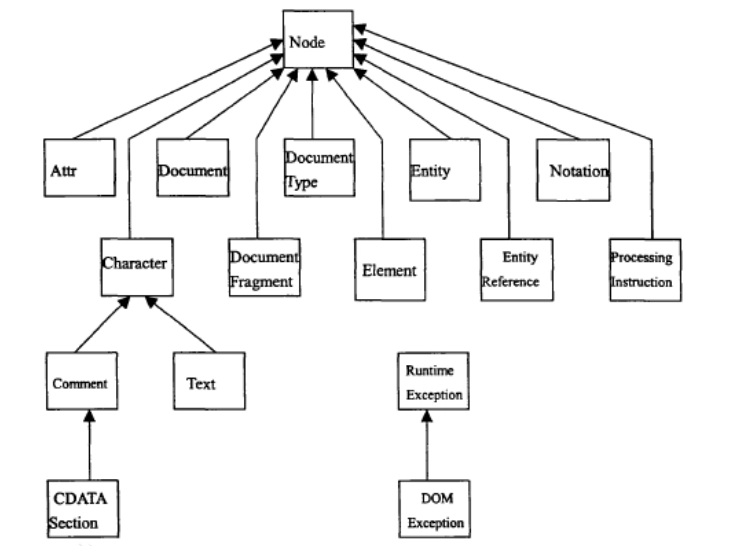
图2 接口之间继承的关系
主要的接口有:
Node接口:它是文档中节点的基类型。定义了基本的访问和改变文档结构的方法。
Document接口:它代表整个文档。可创建文档中的各种节点(元素、注释、处理指令等),创建的节点中带有一个OwnerDoculnent属性表示创建它们的Document对象。
DocumentFragment接口:它代表文档树的子树,相当一个小型文档。
Attr接口:它代表元素节点的属性。有意思的是它并不认为是该元素节点的子节点,不构成DOM树的一部分。同时也不是DocumentFragment节点的直接子节点。
CharacterData接口:它维护了DOMsitrgn字符串并提供读写操作的接口。但不直接对应文档的某种类型节点。
Text接口:它从CharacterData继承而来。代表元素或属性的一段连续的文本内容。它有一个派生的接口CDATAsection,目的是:CDATASeciton节点的内容将不会作任何转化;使用Node中的nomraliez方法时相邻的Text节点会合并成一个节点,但使用CDATASeciton可避免合并。
Comment接口:它也从CharacterData继承而来。代表注释中的文本内容。
NodeList接口:用于管理有序的节点集。
Entity接口:它代表实体;EntityReference代表实体的引用。
NamedNodeMap接口:用于管理无序的节点集。
DOMImplementation接口:它提供与DOM模型的实例无关的接口。CreateDocument可创建一个Document对象;haseFature可判断DOM实现是否支持某一模块。
Notation接口:它代表文档中的符号定义。
ProcessingInstruction接口:它代表处理指令。
DOMException接口:异常处理。由于程序中的逻辑错误、数据丢失或DOM实现本身不稳定引起的错误。在程序处理过程中,由方法返回一个错误值。接口之间的继承关系可参看图2。
特征
Document Object Model的历史可以追溯至1990年代后期微软与Netscape的“浏览器大战” (browser wars),双方为了在JavaScript与JScript一决生死,于是大规模的赋予浏览器强大的功能。微软在网页技术上加入了不少专属事物,计有VBScript、ActiveX、以及微软自家的DHTML格式等,使不少网页使用非微软平台及浏览器无法正常显示。DOM即是当时蕴酿出来的杰作。
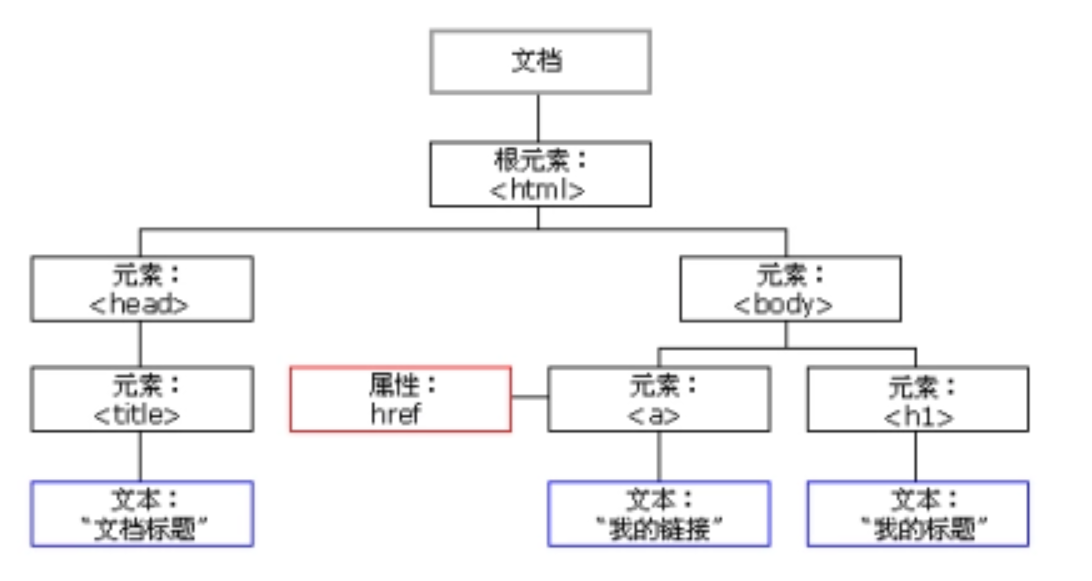
图3 逻辑结构
DOM分为HTML DOM和XML DOM两种。它们分别定义了访问和操作HTML/XML文档的标准方法,并将对应的文档呈现为带有元素、属性和文本的树结构(节点树),如图3所示: 1)DOM树定义了HTML/XML文档的逻辑结构,给出了一种应用程序访问和处理XML文档的方法。
2)在DOM树中,有一个根节点,所有其他的节点都是根节点的后代。
3) 在应用过程中,基于DOM的HTML/XML分析器将一个HTML/XML文档转换成一棵DOM树,应用程序通过对DOM树的操作,来实现对HTML/XML文档数据的操作。
参考资料
1.基于DOM模型扩展的Web信息提取·中国知网
文档对象模型 相关的文章

“呼应”,又称“呼应网络电话”、“呼应免费电话”是一款网络即时通讯软件,由“北京呼应网络科技有限公司”出品,于2014年1月23日成功上线,支持安卓、iOS系统(iOS版本 名称 “呼应”)。

中原铁道国际旅行社(原郑州铁路局旅游总公司)成立于1993年,注册资金500万元。是铁道部华运旅游集团成员,中国旅行社协会会员,中国老年旅游联合体理事单位,隶属于郑州铁路局旅游集团。 1998年经国家旅游局批准为国际旅行社。 2005年被国家旅游局批准为特许经营中国公民出境旅游组团社,并向国家旅游局足额交纳160万旅游质量保证金。


乌尤尼盐沼在玻利维亚波托西省西部高原内,海拔3,656米(11,995英尺),长150公里,宽130公里,面积9,065平方公里,为世界最大的盐层覆盖的荒原,有“天空之镜”的美称。边缘有盐场,主要盐场间有公路相通。

九龙口风景区是打造里运河文化长廊的又一亮点工程,它位于淮安市主城区西郊,是古运河文化长廊的起始点,沟渠纵横、河网密布,以淮沭新河(二河段)为主体,古黄河、京杭大运河、里运河、盐河、淮涟总干渠、淮沭河东偏、淮沭河西偏交汇于此,形成九水相汇的特殊自然景观。
秦国的政治体制在战国时期已经基本形成,灭六国完成统一后,秦始皇嬴政建立起中国历史上第一个专制主义中央集权的郡县制国家,历史上称为秦朝。秦朝建立了以皇帝为首的高度集中的政治体制,它与之前的秦国制度有所不同,也为后世历朝沿袭,其监察制度与九卿制度甚至延续到中国的最后一个朝代—清朝。

特许权费,可以理解为特许经营某种商品或服务收取的费用,例如奥运特许商品,收取特许权费,特许经营商按照销售额的一定比例向奥组委支付特许权费。特许权费的比例一般为商品零售价的5-15%。属于提供设备和其他有形资产的特许权费,在交付资产或转移资产所有权时确认收入;属于提供初始及后续服务的特许权费,在提供服务时确认收入。

王爱伦(Ellen Wong),1985年参加香港无线电视举办的香港小姐获得季军,同年代表香港到日本参加国际小姐,进入15名并获得二十一世纪服装奖第一名,后多次出席香港小姐评判。



无人潜艇,是一种海中军事武器,实际上就是在海中作业的机器人。作为一种水下尖端武器日益受到世界各国青睐,其发展十分迅速,尤其智能化等关键技术的突破和应用,将令未来海战场大为改观。其主要类型有:遥控潜水艇型无人潜艇;半浮半沉型无人潜艇;智能型无人潜艇。